Paper : EfficientDet: Scalable and Efficient Object Detection, 2020 CVPR
Code Repository
- (Official) https://github.com/google/automl/tree/master/efficientdet
- (Pytorch) https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch
- (Tensorflow) https://github.com/xuannianz/EfficientDet
EfficientDet은 google brain팀이 개발한 EfficientNet을 backbone으로 개발한 object detection 모델로 CVPR 2020에 공개되었습니다.
당시 SOTA의 성능을 낸 모델로, 주요 contribution은 1)새롭게 제안한 Feature Pyramid Network구조인 BiFPN에 multi-scale feature fusion개념을 더해 scale에 따라 feature fusion weight를 달리 해준 부분과 2)architecture 속 다양한 스케일을 조합한 Compounding Scaling입니다. 3)그리고 backbone으로 EfficientNet을 전체 architecture scale에 맞게 적용한 부분도 뽑고 있습니다.
본문에서 언급하는 Compounding Scaling은 backbone인 EfficientNet(ICML 2019)의 main contribution에도 기술된 내용인데,
EfficientDet에서는 이뿐만 아니라 BiFPN, prediction network 등의 one stage object detection architecture의 각 파트마다의 scalability를 확보까지 확대되었습니다.
본 리뷰는 6개의 파트로 나누어 작성하였습니다.
- Performance
- Model Architecture
- EfficientNet
- BiFPN
- Compounding Scaling
- Conclusion
1. Performance
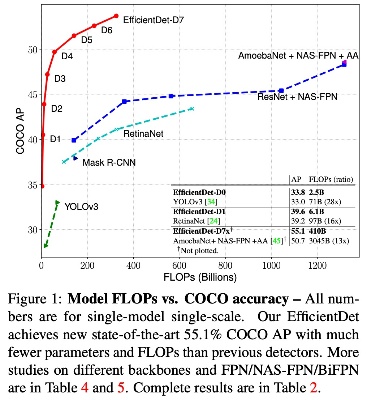
먼저 EfficientDet의 Accuracy Performance부터 살펴보겠습니다. 그림에서 EfficientDet은 이전 SOTA모델인 AmoebaNet+NAS-FPN에 비해 거의 10배 적은 FLOPs에도 유사하거나 더 높은 정확도를 달성을 보여주었습니다.
이런 높은 수준의 Accuracy를 유지하면서도 연산량과 속도, 메모리 등과 같은 주어진 환경에 따라 scale을 변경해가며 사용가능한 모델라인을 구축한 것을 보여줍니다.
2. Model Architecture
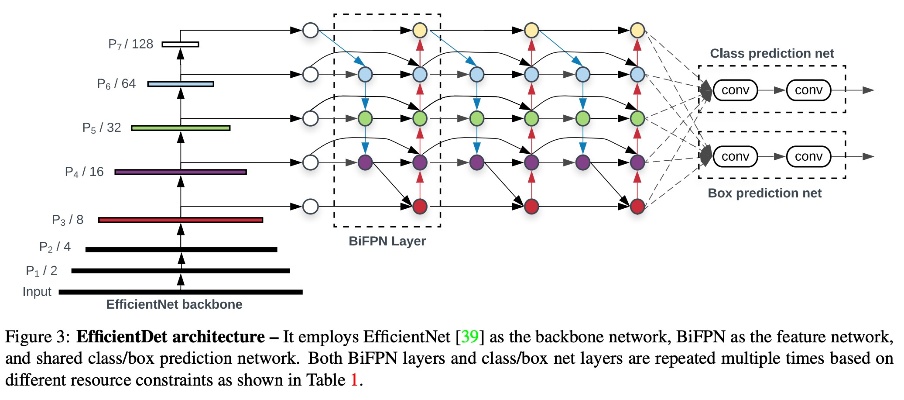
Model Architecture는 One stage object detection 형태의 Backbone + Neck + Head 이렇게 세 파트로 구성되어 있습니다. Backbone에는 EfficientNet의 imagenet pretrained mdel을 초기값으로 사용하였고, Neck은 BiFPN Layer가 반복 사용되었고, Head에서는 classification과 regression network가 사용됩니다. 세 파트 모두 compounding scaling에 포함되어 scalability를 확장할 수 있습니다.
3. EfficientNet
EfficientDet 모델은 Compounding Scaling을 통해 accuracy와 efficient를 모두 최적화합니다. 이는 EfficientNet에서 언급한 Compounding scaling 메카니즘 기조는 그대로 이어오고 있습니다.
EfficientNet에서는 width, depth, resolution을 compounding scaling하였다면, EfficientDet에서는 BiFPN, prediction network에 대해서도 compounding scaling 해주었습니다.
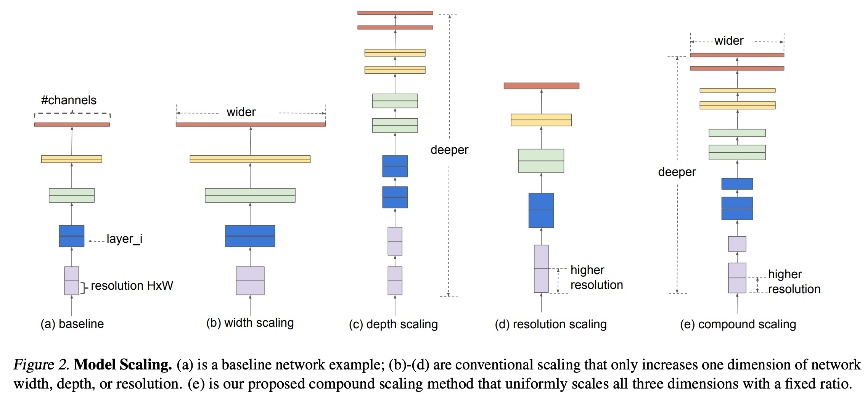
EfficientNet에서 다룬 width, depth, resolution scaling의미는 다음과 같고, 이때 각각을 독립적으로 up scaling해주는 것보다는 다같이 묶어서 up scaling해주었을때 성능이 가장 좋음을 보여주고 있습니다.
Width scaling:Width scaling은 channel 수를 늘려서 scale-up 하는 방법으로 대게 작은 크기의 모델입니다. 기존 연구에 따르면 width 를 넓게 할 수록 미세한 정보(fine-grained feature)들을 더 많이 담을 수 있다고 합니다.
Depth scaling: Depth scaling은 layer 의 수를 늘려서 scale-up 하는 방법으로 Deep Learning 이후 가장 기본적인 scaling 방법입니다. 깊은 신경망은 더 좋은 성능을 달성 할 수 있으나 신경망을 계속 깊게 쌓는 것은 성능 향상의 한계가 있습니다.
Resolution scaling: Input image의 해상도 역시 architecture scale에 맞춰 조정해주었습니다. Depth가 깊어짐에 따라 feature 압축이 많아지게되고 input image resolution이 낮을 경우 정보 희석이 많이 일어나 같이 scale up을 해주는 것이 전체 architecture의 효용을 높이게 됩니다.
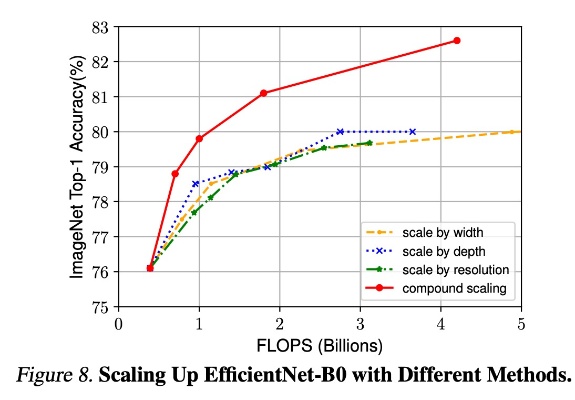
Compound scaling: 위에서 제안한 width + depth + resolution를 compound하여 약속된 scale factor로 다같이 scale up해주었을때 성능이 가장 좋은걸 확인할 수 있습니다.
4. BiFPN
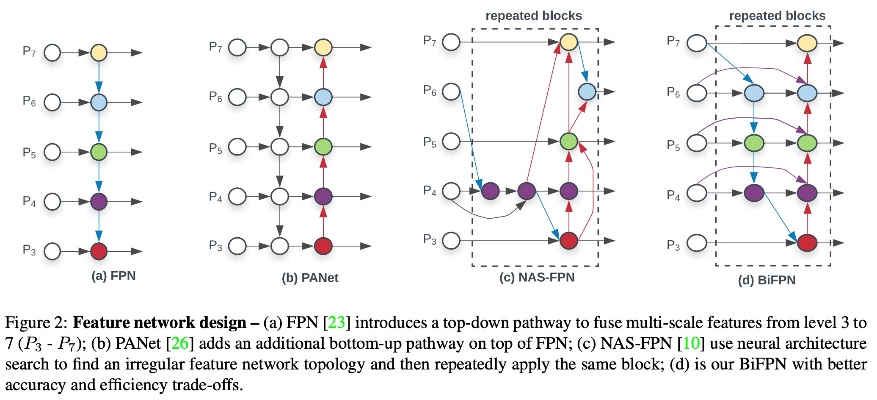
이전 network를 살펴보면, (a) FPN은 backbone에서 추출한 feature에 대해 up scaling convolution을 통해 top-down path의 multi-scale feature fusion으로 성능을 높였습니다. (b) PANet은 FPN에 bottom=up path fusion을 추가해주어 추가적으로 성능을 높였고, (c) NAS-FPN은 강화학습 기반의 NAS를 통해 찾은 FPN구조로 해석하긴 어렵지만 skip connection과 reapeated block을 통해 성능을 높인 부분이 특이점 입니다. (d) BiFPN(Bi-directional Feature Pyramid Network)은 이름에도 알 수 있듯이 양방향 FPN으로 PANet과 유사하게 top-down path와 bottom-up path의 fusion을 모두 사용해주었습니다.
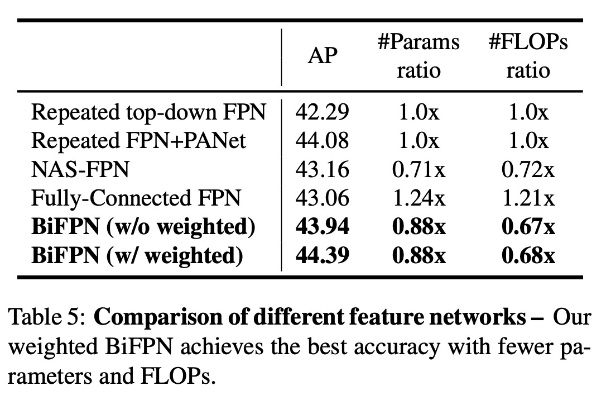
위 실험 결과에서 PANet은 더 높은 정확도를 얻을 수 있지만 더 많은 계산이 필요합니다.
PANet과의 차별점은 크게 4가지로 볼 수 있습니다.
- Delete two layer block : 입력 노드(두 번째 계층 P3, P7)를 Delete하여 하나만 갖는 것입니다. 왜냐하면 이 node는 output 정보 전파에 항상 기여도가 낮기 때문입니다.
- Add skip conneciton: Skip connection을 더해 파라미터의 추가없이도 다양한 feature를 조합하여 효율을 높였습니다.
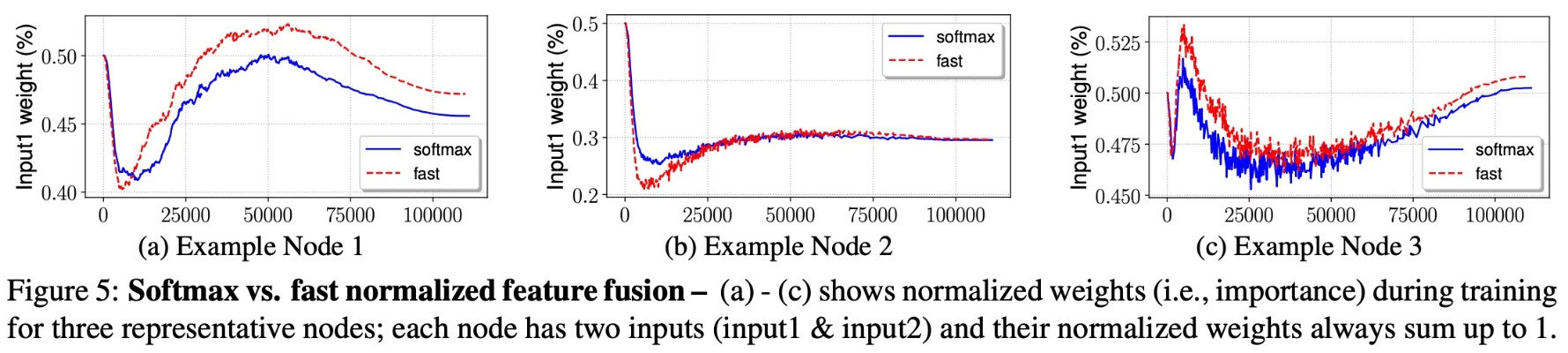
- Weighted feature fusion : input image의 resolution에 따라 output에 기여하는 정도를 달리하기 위해 FPN내 각 cross-scale connection에 독립적인 weight를 추가하여 fusion ratio를 학습시켜주었습니다. 이때 weight를 nomalize를 해주어 특정 connection에 대한 비정상적 가중을 방지하였고, 연산속도를 높이기 위해 softmax 대신 fast nomalized fusion 사용하여 유사 성능에 약 30% 속도 향상을 보였습니다.
- Softmax-based fusion : $O=\sum_{i}\frac{e^{w_{i}}}{\sum_{j}e^{w_{j}}}$
- Fast normlized fusion : $O=\sum_{i}\frac{w_{i}}{\epsilon + \sum_{j}w_{j}}$
![]()
- Repeat BiFPN Layers : NAS-FPN과 같이 repeat block을 사용하였습니다.
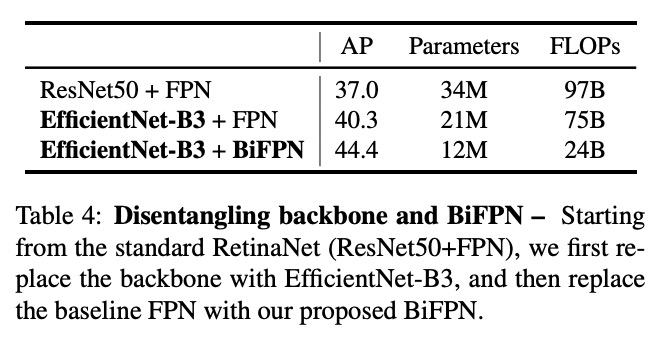
BiFPN을 보며 한가지 의문점이 FPN보다 구조도 복잡하고 reapeated block으로 network 규모도 더 커지는 것 같은데 어떻게 FLOPs가 줄었을까였습니다. 본문을 보니 BiFPN내 모든 convolution을 depth-wise-seperable convolution으로 치환하여 FLOPs를 대폭 줄인것으로 보입니다.
5. Compounding Scaling
EfficientDet은 아래의 각 scaling요소를 HPO하여 성능을 최적화 하였습니다. Random HPO시, Parameter 분포가 너무 넓기 때문에 grid search를 통해 $\phi$ 에 따라 search하도록 설계하였습니다.
- Backbone network : EfficientNetB0 ~ B7을 사용하였습니다.
- BiFPN network : channel 수와, BiFPN Blcok의 반복 횟수를 scaling 하였습니다.

- Box/class prediction network: box prediction과 class prediction에 사용되는 network에 대해 공통적으로 3개부터 시작하여 정수개의 layer를 추가하며 scaling합니다.
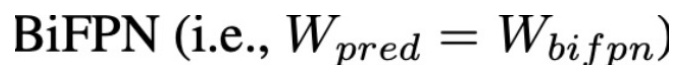
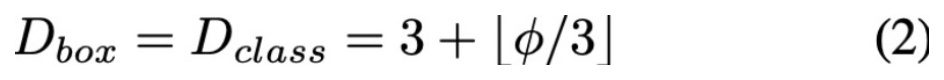
- Input image resolution : FPN에서 strike에 따른 feature size 압축이 일어나게 되고, 512 점점 scaling을 키워줍니다.
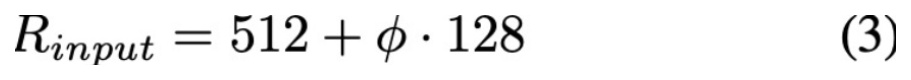
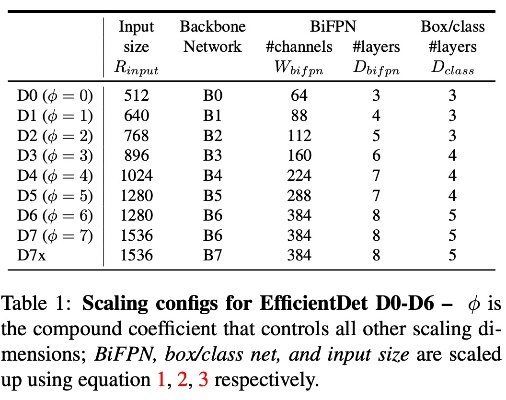
- Scaling Configs : 위 scaling factor에 대한 grid search optimize된 parameter는 아래 표와 같습니다.
- Scaling Performance : Compound scaling에 따른 성능 비교
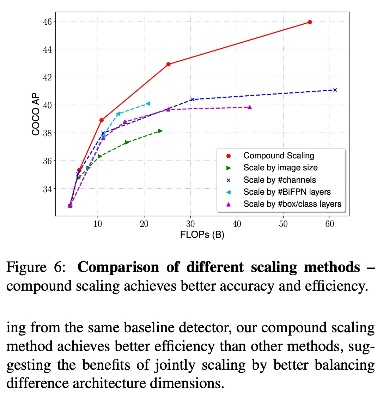
6. Conclusion
- Accuracy와 Efficiency향상을 위해 customized compounding scaling과 weight BiFPN을 제안하였습니다.
- EfficientDet은 이전 모델보다 좋은 성능을 가질 뿐만 아니라 넓은 스펙트럼을 갖습니다.
- 매우 적은 FLOPs만으로도 유사 성능을 내는 모델을 구축하였습니다.